BirdCLEF 2021 - Birdcall Identification
BirdCLEF 2021 is a data science competition for identifying bird calls in soundscape recordings. The goal is to be able to identify the species of bird making a call in a 5-second window in a soundscape audio track. The competition started on April 1, 2021, and the final submission deadline will be May 31, 2021.
The LifeCLEF 2021 conference will be held later this year from September 21-24, 2021. Placing in this contest could result in some exciting things.
2021-04-06
I’ve done a little bit of research into the topic. The training dataset contains over 350 different bird species, where each species has over one hundred one-minute audio clips that feature the bird call. Since the goal is to identify a 5-second clip, it seems like this problem boils down to building a cleaned-up training set from the audio. My approach will go something like this:
- In the first phase, I will be looking at a single audio track and extracting 5-second clips that identify the bird.
- In the second phase, I will be extracting patterns from the rest of the tracks in that particular species. I should end up with several thousand thumbnails that I can use for training. In the third phase, I’ll repeat the first two on the bird species’ rest.
- In the fourth phase, I’ll train a linear classifier to return the bird call in the training set. It seems unlikely that there will be more than one bird per segment.
- In the final phase, I’ll attempt to make an initial submission.
It will take some time to build a simple model, but I aim to spend about a month on this task. I have several other things going on outside of work that I need to dedicate a little bit of time. I think this should take about 20-30 hours to get to my first submission.
I’ve done some initial investigation into motif-mining for time-series data. I’m going to take the approach of using the Matrix Profile, which has a lot of desirable properties. In particular:
- Silva, D. F., Yeh, C. C. M., Batista, G. E., & Keogh, E. J. (2016, August). SiMPle: Assessing Music Similarity Using Subsequences Joins. In ISMIR (pp. 23-29). [pdf]
- Silva, D. F., Yeh, C. C. M., Zhu, Y., Batista, G. E., & Keogh, E. (2018). Fast similarity matrix profile for music analysis and exploration. IEEE Transactions on Multimedia, 21(1), 29-38. [pdf]
- Yeh, C. C. M. (2018). Towards a near universal time series data mining tool: Introducing the matrix profile. arXiv preprint arXiv:1811.03064. [pdf]
The first two links describe SiMPle, which adapts the Matrix Profile to music analysis. It uses the chroma energy normalized statistics (CENS) to compute the profile using 2 to 10 CENS depending on the task.
In the last link, section 3.3.3 on Music Processing Case Study is the most relevant. It uses mSTAMP (a multi-dimensional generalization of the Matrix Profile) to discover multi-dimensional motifs from the Mel-spectrogram taken with 46ms STFT, 23ms STFT hop, and 32 Mel-scale triangular filters. It is able to distinguish both the chorus and the drum-beat, depending on the dimensionality of the pattern.
I did a little bit of testing using librosa and matrixprofile. I tried this out in a notebook to see what would come out.
import librosa
import matrixprofile as mp
%matplotlib inline
path = "../input/birdclef-2021/train_short_audio/acafly/XC109605.ogg"
data, sample_rate = librosa.load(path)
cens = librosa.feature.chroma_cens(data, sample_rate, n_chroma=36)
profile, figures = mp.analyze(y)The matrixprofile library is complete, but it doesn’t contain algorithms for
either mSTAMP or SiMPle. The R-library
tsmp has implementations
for both of these, but the audio-processing libraries are limited (either
audio or
tuneR). I may end up
doing the audio processing with librosa and the matrixprofile computation and
motif mining in R as a pipeline. When this gets out of hand, or when I need to
run the process in Kaggle, I can re-implement the SiMPle algorithm in Python.
2021-04-07
est: 1-2 hours
I spent my time today getting the environment set up on my local machine. I downloaded the 32GB dataset last night and tried unpacking it on my 1TB HDD before eventually giving it up since it was unpacking at a rate of 13mb/s or so. I moved this to my SSD.
I set up my environment, which is Jupyter Lab configured with Python and R. On
the Python end, I have a small script that dumps the .ogg files into
serialized NumPy matrices (.npx). I wanted to reproduce the setup used with
audio spectrograms via CENS at a rate of 2-10 frames per second. It turns out
that the hop_length has to be a multiple of .
This function takes care of quantizing to the nearest integer multiple.
def cens_per_sec(sample_rate, target):
"""Ensure the hop length is a multiple of 2**6"""
return (sample_rate // (target * (2 ** 6))) * (2 ** 6)I also set up R with Jupyter Lab by following this guide for installing the R
kernel.
I had to add the directory containing R.exe into my PATH, and ensured that the
current shell had my virtual environment configured. Then:
install.packages("devtools")
devtools::install_github("IRkernel/IRkernel")
IRkernel::installspec()Afterwards, I just load this into an R notebook so I can run some pre-existing Matrix Profile algorithms. I am able to load the numpy serialized data through RcppCNPy.
2021-04-08
I only made minor progress today. I plot the data after running it through the SiMPle algorithm:
library(RcppCNPy)
library(tsmp)
fmat <- npyLoad("../data/cens/train_short_audio/acafly/XC109605.npy")
smp <- simple_fast(t(fmat), window_size=41, verbose=0)
plot(smp)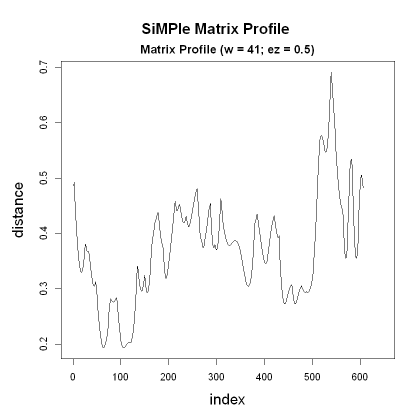
It turns out that the object class name is not usable with the majority of the
tsmp library because a typo in the class name, despite it having a perfectly
good Matrix Profile and Profile Index object for determining motifs and
discords.
SiMPle Matrix Profile
---------------------
Profile size = 606
Dimensions = 12
Window size = 41
Exclusion zone = 21Looking at the source code for find-motifs in the tsmp
library,
we see that the class type is enforced by string names…
if (!("MatrixProfile" %in% class(.mp))) {
stop("First argument must be an object of class `MatrixProfile`.")
}🤦 There’s no space in the name. I forked the library to acmiyaguchi/tsmp and will make a PR to fix up this behavior for this algorithm. I rather not have to deal with some of the common functionality by hand, even if it’s simple like finding the pairs of indices that correspond to a motif.
I’ve also been thinking about how to to use the motifs to search for 5 second clips that I can use to build up my training dataset. Since I’ll be getting only a single motif per audio track, I’m going to fetch many motifs from the species dataset to get a motif per track. I can analyze these motifs to see how well they stack up to each others.
After I find these initial motifs, I can comb through the rest of the audio to determine what other clips can be found. I can use the median-absolute deviation effectively slide over all of the tracks and to find the positions where there are likely matches in the audio.
2021-04-09
While the mechanism wasn’t exactly what I thought it would be, it was similar enough. I learned a little bit about the inheritance mechanisms in R.
devtools::test(filter="simple")Afterwards, I created a PR and installed my package from GitHub (after killing all existing kernels to avoid permission issues).
devtools::install_github("acmiyaguchi/tsmp", ref="simple")Unfortunately, this did not work on a realistic matrix because the find_motif
method also does nearest-neighbor computation, which requires calling
MASS to determine
which indices are most related to each motif. The SiMPle MASS algorithm is
domain specific, so it did not fit directly into the existing API for other
Matrix Profiles :(.
I decided to abandon the find_motif helper and just to use the motif
corresponding to the minimum in the profile. I can get to this using
min_mp_index which works fine on SiMPle. I would have used the thumbnail that
I extracted from the motif pair (e.g. the 5 seconds of audio corresponding to
the motif to find nearest-neighbors), but when I try to compute the join
matrix-profile, it raises an index error:
Error in last_product[1:(data_size - window_size), j]: subscript out of boundsThis is a distraction at this point. Since I get two examples per track and there are roughly a hundred tracks per species, this should be enough to build an initial model. Once I get an initial model, I can try out a few different methods to get more training data. I really wish I had access to the join matrix-profile, but I can try other methods like training a classifier on the spectrograms using a sliding window of data.
I built an R script that I’ll be calling via Python to find the index of the motifs. These links were relevant as I put it together.
- https://stackoverflow.com/questions/18931006/how-to-suppress-warning-messages-when-loading-a-library
- https://stackoverflow.com/questions/19894365/running-r-script-from-python
- https://stat.ethz.ch/R-manual/R-devel/library/base/html/strtoi.html
- https://www.gastonsanchez.com/r4strings/formatting.html
Then I was able to build a notebook to listen to the motifs. Jupyter has a nice API to embed audio in a notebook. Here is a pair off motifs from audio of the Acadian Flycatcher.
2021-04-10
I scripted together the above to extract motifs from the acafly directory. In each of these, I have the following files:
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a---- 4/11/2021 12:31 AM 362 metadata.json
-a---- 4/11/2021 12:31 AM 435320 motif.0.npy
-a---- 4/11/2021 12:31 AM 32156 motif.0.ogg
-a---- 4/11/2021 12:31 AM 435320 motif.1.npy
-a---- 4/11/2021 12:31 AM 31789 motif.1.oggThe ogg files contains the 5 second clip of the main motif. The numpy files are the CENs transformed data for the motif. The metadata file contains information about the different parameters used to extract the motif:
{
"source_name": "train_short_audio/acafly/XC533302.ogg",
"cens_sample_rate": 10,
"matrix_profile_window": 50,
"cens_0": 50,
"cens_1": 1,
"motif_0_i": 108797,
"motif_0_j": 217595,
"motif_1_i": 2175,
"moitif_1_j": 110973,
"sample_rate": 22050,
"duration_seconds": 17.07,
"duration_cens": 173,
"duration_samples": 376441
}It looks like I’ll have to go through each file by hand to determine whether it’s a legitimate bird call or not. I’ve noticed that some clips have a motif that is noise or another natural sound. It looks like I’m going to become a bird-call novice. It should be straightforward to build a web application to do the labeling of the data. How much of the code I’ll be able to re-use is up in the air, but I rather not have to deal with all the information in a spreadsheet.
Once I can deal with these particular audio files, I can start to build an even more extensive dataset to determine whether a file has the bird chirp in it or not. I’ll try to aim for something like an extra 100 examples that I can trawl randomly sampled from the set. Building a simple classifier will be good practice for building more complex ones later.
I think once I build this initial dataset, it will be useful to come back and reimplement (or fix) the SiMPle algorithm so I can do two things:
- find the top k motifs
- run the matrix profile join against short clips
The classifier I build on this first one will help filter out the noisy values, while the latter will help me find more examples throughout the dataset. This approach should surely scale for finding good examples.
2021-04-11
I took the motifs that I generated for acafly and osprey and created a web application that I’m going to use to explore and label the data. I used sveltekit to build this, since I’ve had experience with both svelte and sapper. I’m pleased with the template and how little frill is involved. It’s going to take some time before I get used to the paradigm.
figure: screenshot of the the current page
There are minor issues like not being able to import the node-glob module and
having to explicitly set preload="none" on the audio context, but otherwise
it’s been smooth sailing.
I think creating a training dataset based on these motifs and the system for labeling the data will be my main contribution to the competition. I’m not so confident that I’ll be able to build better models than the previous year. I’m probably going to rely on an ensemble model that uses many simple linear models under the hood, because I’m not sure I can figure out the intricacies of CNN models.
I also read a couple of the previous BirdCLEF papers, which I’ll leave a link here for reference.
- http://ceur-ws.org/Vol-2696/paper_262.pdf
- http://ceur-ws.org/Vol-2380/paper_256.pdf
- http://ceur-ws.org/Vol-2125/invited_paper_9.pdf
2021-04-11 Adding metadata to the website
est: 2.5 hours
Did a little more on the site today. First I took a look at the training
metadata and created documents that I can use for building the site. In the
info.json:
{
"primary_label": "tropew1",
"scientific_name": "Contopus cinereus",
"common_name": "Tropical Pewee"
}And an entry from the metadata.json:
{
"name": "XC11419",
"secondary_labels": [],
"type": ["call"],
"date": "2004-06-05",
"latitude": -22.5001,
"longitude": -42.7167,
"rating": 4.5,
"url": "https://www.xeno-canto.org/11419"
}Then, I went about joining these pieces of information in the application. I brought in a table component so the number of things being rendered on the page at once is limited to 10 or so entries.
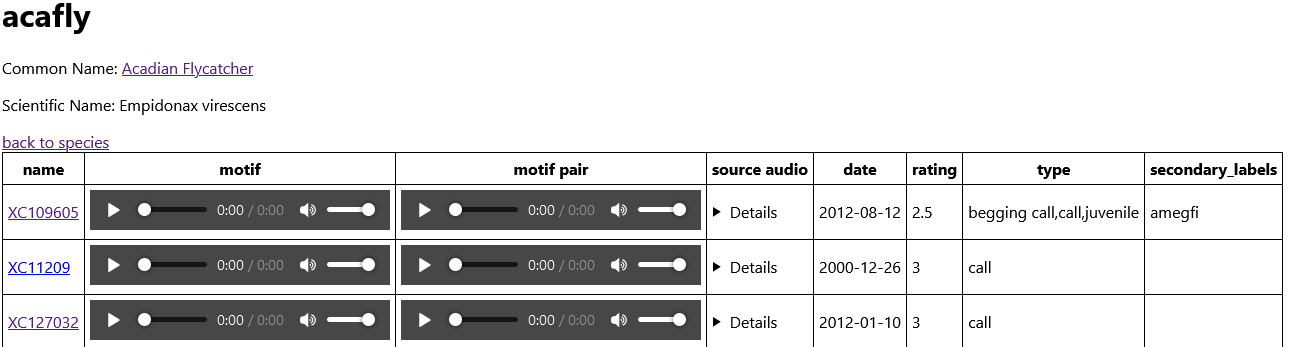
The next thing that I need to do is add a way to label whether an entry is good or bad and have a way to export that. I want to start quickly building a classifier to determine whether a clip is a bird call or not, so I can start to go toward my first submission.
2021-04-15 Adding labeling support
est 2 hours
I had to do a bunch of refactoring to add support to the table to include two
checkbox inputs that are hooked to an object in indexedDB via localforage. I
also added a way to export this data via file-saver. I’m going to start
labeling some data so I can move onto the next phase of development.
[
{"name":"XC109605.motif.0","is_valid":true},
{"name":"XC109605.motif.1","is_valid":true},
{"name":"XC11209.motif.0","is_valid":true}
...
]I’d like to have some way to bookmark my progress. I should probably annotate the rows somehow. It might be as easy whether I’ve listened to a particular audio clip.
2021-04-17 - 2021-04-19 struggles and triumphs
I did a lot of exploration this weekend. I finished up the tool to look through the audio clips and annotate them with information. I went through an entire species of motifs of 256 5-second clips. It was a useful exercise, since I know what to listen for now.
I also started trying to cluster and classify the motifs from a single species and three species. My first approach was to reduce the dimensionality using SVD, cluster using K-means as labels, and then plot. I used Nearest Neighbors to listen to the points closest to the k-means to see how well the embedding worked. It was pretty awful because there were logical characteristics from each of the groups.
Adding in multiple species and using those at labels has poor results too. I trained a simple logistic regression classifier and got a result around 0.55. I think I’ll end up getting a result around 0.7 by the time I’m finished.
See:
- https://github.com/acmiyaguchi/birdclef-2021/blob/main/notebooks/2021-04-17-clustering.ipynb
- https://github.com/acmiyaguchi/birdclef-2021/blob/main/notebooks/2021-04-17-clustering-multiclass.ipynb
- https://github.com/acmiyaguchi/birdclef-2021/blob/main/notebooks/2021-04-17-classification-one-vs-rest.ipynb
I took a look through a couple papers to figure out how I might find similarity between these motifs.
Englmeier, D., Hubig, N., Goebl, S., & Böhm, C. (2015). Musical similarity analysis based on chroma features and text retrieval methods. Datenbanksysteme für Business, Technologie und Web (BTW 2015)-Workshopband. https://www.medien.ifi.lmu.de/pubdb/publications/pub/englmeier2015btw/englmeier2015btw.pdf
- create audio words using tf-idf and a chromagram
Wankhammer, A., Sciri, P., & Sontacchi, A. (2009). Chroma and MFCC based pattern recognition in audio files utilizing hidden Markov models and dynamic programming. In Proceedings of the 12th International Conference on Digital Audio Effects (DAFx-09) (pp. 401-407). https://phaidra.kug.ac.at/open/o:11903
- do pattern recognition via HMM, transitions between segments in the audio
Late Saturday, I decided that I found go with the initial approach and try to classify based on the median similarity to to a set of representative motifs. For this, I needed to be able to compute profiles with sample queries. I fixed an issue with the SiMPle implementation in tsmp, and also figured out how to get the the reference Matlab implementations running in Octave. I spent most of Sunday re-implementing the algorithm in Python. It works and has results that matches both implementations using a single bird call.
The challenging parts of implementing:
- Getting the reference implementations to match up. I used the existing chromagrams that I dumped for the various bird species and dumped them in a folder and decided to go with CSV to match them up.
- Matlab and R use 1 indexing, while Python and numpy use 0 indexing. This was a pain because it took me a while to realize that the slicing behavior is different for the starting index.
- The FFT implementation in
numpy.fftuses the last dimension when computing 1d ffts in a matrix. Also, the 2d fft is not the same thing (d’oh). I could have saved a lot of time if I had written the tests formass_prewhich computes the FFT and the cumulative sum first. Oh well.
I would like to patch the tsmp library, but I’m not sure what the best way to add tests will be. Probably generated fake data of some sort.
Now I will find a representative set of motifs for each species. I’m going to take the same clustering approach as before, but this time I will use a similarity matrix using a manifold (probably a spectral embedding). This means I’ll need to do O(n^2) comparisons, but the number of motifs is only in the order of the number of training examples. I’ll also be able to mine many examples for each species, which should make training a real model (like a CNN) computationally easy.
2021-04-19
Spent my time playing with the simple implementation I made. I need to integrate it with my motif-finding script (which also needs to be parallelized). I took a look at trying to find representative audio clips by doing an AB join with every motif to every other motif. I embed the affinity matrix directly into the spectral embedding algorithm. The initial plots look reasonably spread out unlike the PCA plots from before.
I tried a few different parameters for both the windows using the median. The next stage will be to cluster multiple classes and see how well this works. First I’ll find a few representative samples from each species, and then against each of those samples the distances to every motif in the entire motif dataset.
A few of the motifs near the cluster means sound entirely empty (which might be hubs, since they are equidistant if flat and may have median values that have the same shape as other ones). The minimum might be another value to try, since that seemed to be how motifs are found in the self-join. I need to spend another 1-2 hours trying to grok this. I also need a no-call detector, which may be the first thing I have to build because I’m worried about the quality of the automated system. The first way might be to do some outlier detection (which maybe won’t work on this data alone). The other is to do the classifier route and train one on a bunch of no-calls from the soundscapes.
2021-04-20 multi-class classfication
I ported over my python implementation to the find_motif script and
parallelized it. It takes only a minute or so to complete per species (which
means that I’ll be able to go through all of the species in a reasonable amount
of time). I tried embedding 3 classes into a single space using the all-pairs
methodology, but there was no clear delineation. I believe that the empty tracks
are causing issues and acting like hubs.
I’m going to go ahead with the terrible model first, which I’ll train with XGBoost. The terrible model will have 2-3 entries for each species (which ends up being something like 400 entries). Actually, on second thought, it might take forever to train a model if there are a large number of examples (easily 10k+). I might have to go the CNN route to generate features to feed into the XGBoost model. Maybe I can just feed the features directly into the model, alongside the self-join of the clip.
Here’s the experiment I want to run on a soundscape.
XGBoost model:
- Binary classification of call/no-call
- 5 second clips (10 CENS/sec)
- Model trained directly on CENS
- Model trained with matrix profile with window of 5, 10, and 25 (distances to the nearest neighbor) using the median.
- Model trained with both
- https://arxiv.org/pdf/1804.01149.pdf
- https://www.sciencedirect.com/science/article/pii/S1738573319308587
2021-04-21
- https://arxiv.org/pdf/1412.6806.pdf
- https://stackoverflow.com/questions/19125661/find-index-where-elements-change-value-numpy
I spent most of my evening installing tensorflow. I needed to install the exact versions of CUDA and cuDNN for it to work. There were also issues with the installation of Python that I was using, which was installed via the Windows Store. Apparently, this version of Python is sandboxed. After I diagnosed these issues, I was able to run a CNN tutorial that ran on my GPU.
I’m trying to figure out the best way to build a model now. I want to go with a basic CNN first to see what the performance is like. Afterwards, I want to build an auto-encoder to get features from the spectrograms, and then feed the results into a gradient boosted tree for fine-tuning alongside metadata. I read a few papers trying to figure this out…
2021-10-15
After half a year of haitus, I’m deciding to work on this in many tiny peices. I’ve long given up on competing, but this is a dataset with ideas that I haven’t explored yet.
I recently got a new 1TB drive, so I’m moving all my kaggle material off onto it. I was running out of space in a previous iteration because saving the raw mfcc data was costly.
I’ve been taking a look at tile2vec and nnAudio to start with a GPU first approach.
Tile2vec brings the idea of embedding based on triplets of earth tile images. I believe this idea could be extended by treating audio frames like images, and using distance measures from simple in order to bootstrap the embedding process. This way, I should be able to get an embedding that I can use for audio searches.