Inducing Entity Subgraphs from Wikipedia with GraphFrames
Feb 17, 2020 11:50 PMI’ve been toying with the idea of analyzing news through named entities extracted from written articles. A named entity is a real world object that has a proper name (e.g. the Royal Palace of Madrid). A rule of thumb is that if it’s significant enough to have a Wikipedia page, then it’s likely to be a named entity. For the data processing pipeline that I’ve built, I use a recent Associated Press news article about Jimmy Hoffa. I gather a group of entities using a script to parse the page and extract the entities. I clean up the results from the Natural Language Toolkit (NLTK) by passing them into the Wikipedia search API to get a list of article ids and titles.
Id,Label
8687,Detroit
11127,Federal Bureau of Investigation
18995,Martin Scorsese
115009,Kansas City Kansas
158984,Harvard Law School
255722,Jimmy Hoffa
323246,Goldsmith
334010,International Brotherhood of Teamsters
594156,Mafia
1250883,Church Committee
...Now, armed with entities referenced in the Jimmy Hoffa article, I build up a graph of relationships. My approach is to generate an edge (or a link) between the articles if there is a hyperlink between them. I start with the pages and pagelinks data sets that I extracted from the 2019-08-20 dump of English Wikipedia. In this dump, there are 5.9 million articles and 490 million links between them. The pages data set contains metadata about the article, such as the unique identifier and title. The pagelinks data set is an adjacency list that represents the hyperlinks between articles. This is the core of what makes Wikipedia such a great resource for referencing obscure pieces of information. I took some notes on extracting the data from the SQL dumps using the epfl-lts2/sparkwiki project.
With this, I put together a script to generate an induced subgraph of Wikipedia articles referenced in the AP news article. I used graphframes to search for edges, because of prior experience working with the tool. In the domain-specific language, I search for the relationship: (a)->[]->(b). This will return all nodes a and b that are joined by a single unnamed edge.
Here’s a mostly complete fragment demonstrating the use of graphframes.
from pyspark.sql import SparkSession
from pyspark.sql.functions import broadcast, expr
from graphframes import GraphFrame
articles = spark.read.csv("articles.csv")
pages = spark.read.parquet("data/pages")
pagelinks = spark.read.parquet("data/pagelinks")
graph = GraphFrame(pages, pagelinks.selectExpr("from as src", "dest as dst"))
edgelist = (
graph.find("(a)-[]->(b)")
.join(broadcast(ids), on=expr("a.id=article_id"), how="inner")
.drop("article_id")
.join(broadcast(ids), on=expr("b.id=article_id"), how="inner")
.drop("article_id")
.selectExpr("a.id as src", "b.id as dst")
)
(
edgelist.selectExpr("src as Source", "dst as Target", "1 as Weight")
.coalesce(1)
.write.csv(f"edges", header=True, mode="overwrite")
)One of the neat properties of running graphframes is that the queries are run through Spark’s optimizer. In the query plan below, the self-join on the pagelinks dataset against the input articles is evident.
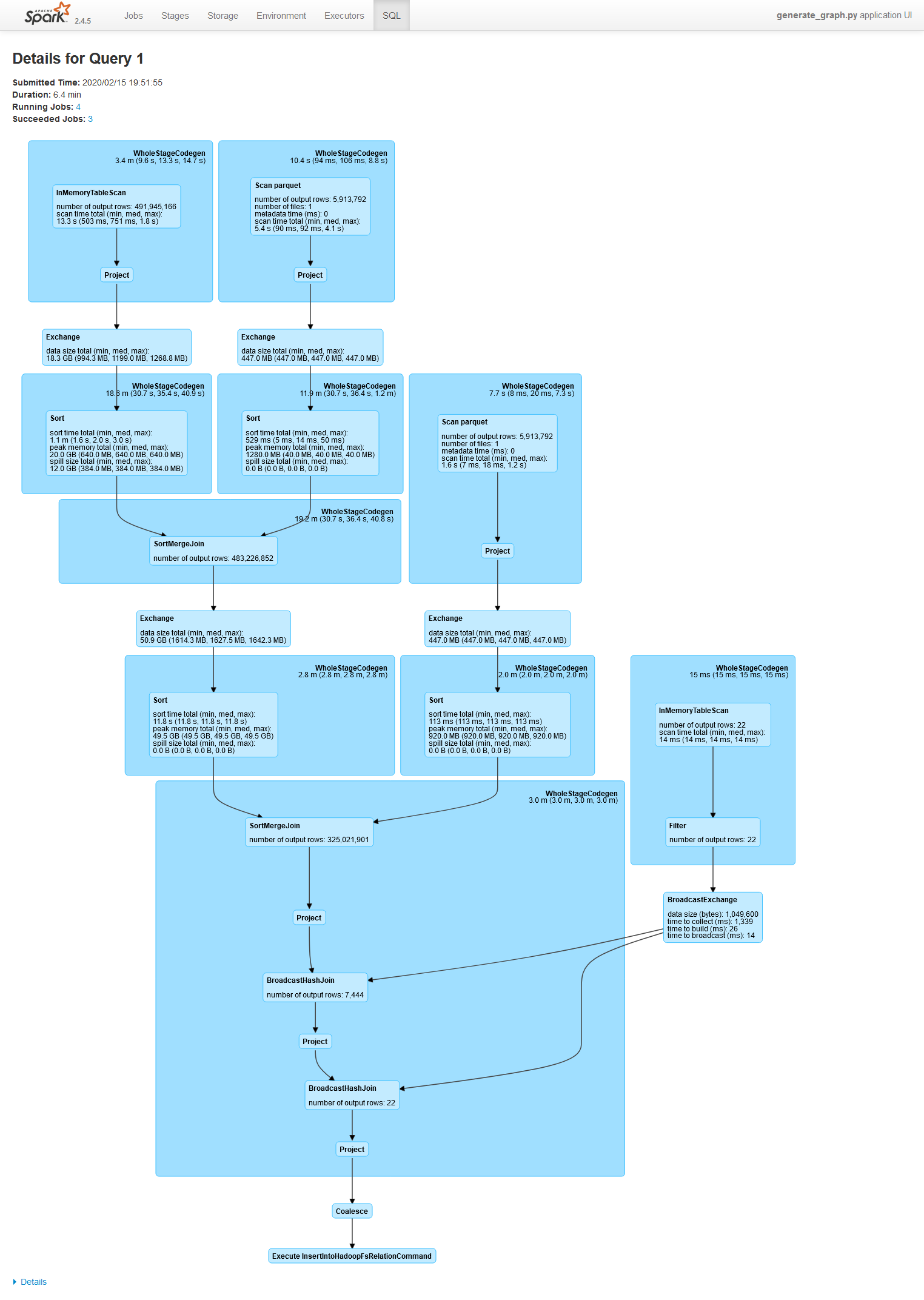
This page is useful for understanding what is happening underneath the hood, and where parameters can be tuned to increase performance. To actually run the job, I use the following Powershell script to wrap spark-submit. Note that SPARK_HOME is set to the local directory of pyspark installed via pip (e.g. pip install pyspark).
$filename = "scripts/generate_graph.py"
$env:SPARK_HOME = $(python -c "import pyspark; print(pyspark.__path__[0])")
spark-submit `
--master 'local[*]' `
--conf spark.driver.memory=24g `
--conf spark.sql.shuffle.partitions=32 `
--packages graphframes:graphframes:0.7.0-spark2.4-s_2.11 `
$filename @argsThis job completes in roughly 10 minutes on my desktop. In a later diversion, I tested a version of this script on a n1-standard-16 machine with a local SSD in Google Cloud Dataproc that took 3 minutes
The result is an edge table that can be imported directly into Gephi, a tool for graph analysis and visualization.
Source,Target,Weight
158984,17003967,1
19571,8687,1
255722,8687,1
10687798,18995,1
43792007,18995,1
255722,18995,1
...With a few tweaks to compute communities, we get a visualization of the entity graph from the news article.
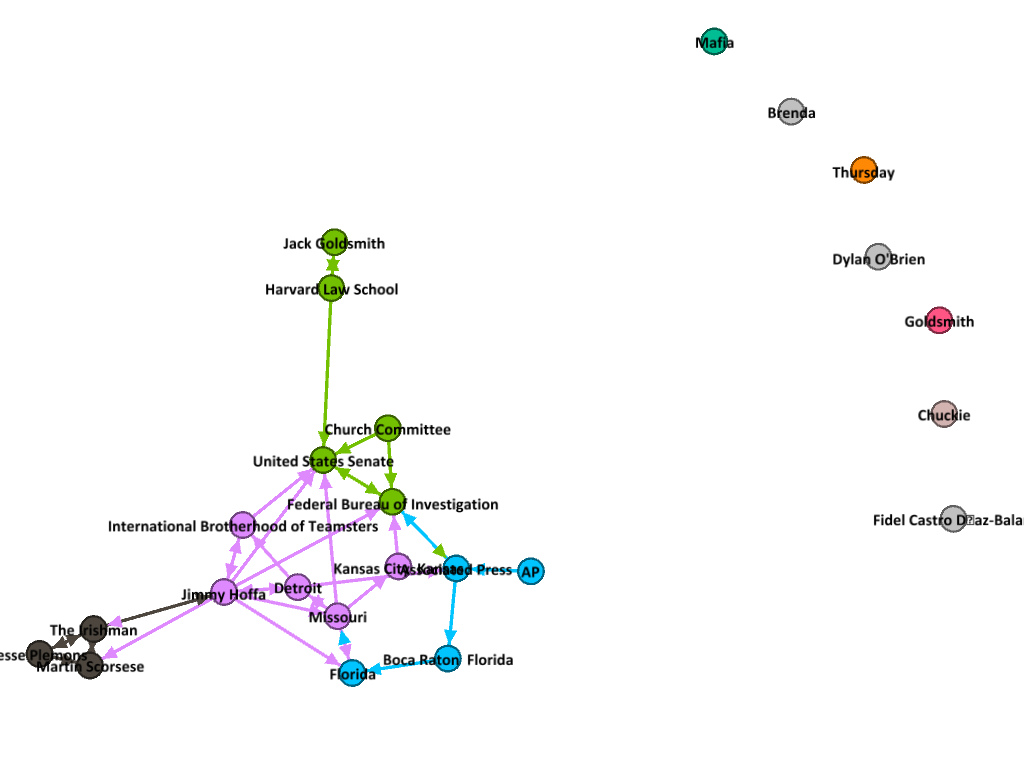
I’m still hacking away at this code, so there are some areas that I’d like to write about in more detail. For example, computing second-order relationships in the graph requires more memory than I have locally (1TB of SDD and 2 TB of HDD). BigQuery has solved my memory issues, but it does require setting up the pipeline differently.
I am also aiming to do a bit of network analysis, in particular about the geometric shape of these entity graphs. I have been researching graphlet-based measurements, which have applications in determining similarity in protein-protein interaction and global-trade networks. Based on the over (or under) expression of certain graphlets, the Jimmy Hoffa article I used for this post might fall under “Obituaries” based on the entities involved. Even if measuring the statistic proves fruitless, it will make for an interesting resource for referencing current events.