Data ingestion is a process that involves decompressing, validating, and transforming millions of documents an hour. The schemas of data coming into our systems are constantly evolving, sometimes causing partial outages of data availablility when the conditions are ripe. In this post, I’ll go over how we discovered and backfilled data rejected in our ingestion pipeline due to a small change in the format of a Telemetry ping.
Catching and fixing the error
Every Monday, a group of data engineers pours over a set of dashboards and plots
that are indicative of data ingestion health. On 2020-08-04, we filed a bug where
we observed an elevated rate of schema validation errors coming from environment/system/gfx/adapters/N/GPUActive. For errors like these
that are small fractions of our overall volume, partial outages are typically
not urgent (as in “we need to drop everything right now and resolve this stat!”
urgent). We called the subject experts and found out that code responsible for
reporting multiple GPUs in the environment had changed.
An intern reached out to me about a DNS study that he was running a few weeks after the bug was file. I helped figure out that his external monitor setup with his Macbook was causing rejections like the ones that we had seen weeks before. One PR and one deploy later, I watched the error rates for the GPUActive field drop to zero.
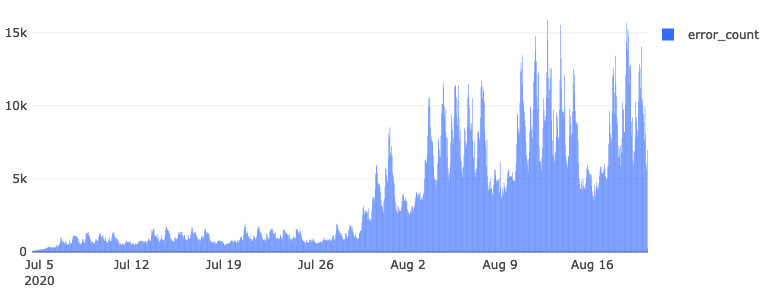 Figure: Error counts for
Figure: Error counts for environment/system/gfx/adapters/N/GPUActive
The mispecification of the schema resulted in 4.1 million documents between 2020-07-04 and 2020-08-20 to be sent to our error stream, awaiting reprocessing.
Running a backfill
In January of 2021, we ran the backfill of the GPUActive rejects. First, we determine the backfill range by querying the relevant error table:
SELECT
DATE(submission_timestamp) AS dt,
COUNT(*)
FROM
`moz-fx-data-shared-prod.payload_bytes_error.telemetry`
WHERE
submission_timestamp < '2020-08-21'
AND submission_timestamp > '2020-07-03'
AND exception_class = 'org.everit.json.schema.ValidationException'
AND error_message LIKE '%GPUActive%'
GROUP BY
1
ORDER BY
1This helped verify date range of the errors and their counts: 2020-07-04 through 2020-08-20. The following tables were affected:
crash
dnssec-study-v1
event
first-shutdown
heartbeat
main
modules
new-profile
update
voiceWe isolate the error documents into a backfill project named moz-fx-data-backfill-7 and mirror our production BigQuery datasets and tables
into it.
SELECT
*
FROM
`moz-fx-data-shared-prod.payload_bytes_error.telemetry`
WHERE
DATE(submission_timestamp) BETWEEN "2020-07-04"
AND "2020-08-20"
AND exception_class = 'org.everit.json.schema.ValidationException'
AND error_message LIKE '%GPUActive%'Now we can run a suitable Dataflow job to populate our tables using the same ingestion code as the current jobs in our production envrionment. It took about 31 minutes to run to completion. Now copy and deduplicate the data into a dataset that closely mirrors our production environment.
gcloud config set project moz-fx-data-backfill-7
dates=$(python3 -c 'from datetime import datetime as dt, timedelta;
start=dt.fromisoformat("2020-07-04");
end=dt.fromisoformat("2020-08-21");
days=(end-start).days;
print(" ".join([(start + timedelta(i)).isoformat()[:10] for i in range(days)]))')
./script/copy_deduplicate --project-id moz-fx-data-backfill-7 --dates $(echo $dates)This query took hours because it iterated over all tables over a period ~50 days, regardless of whether it contained data. Future backfills should probably remove empty tables before kicking off this script.
Now that we have populated tables, we need to make sure to handle any data deletion requests that have come in since the time of the intial error. The self-service deletion requests are served by a module in BigQuery ETL. We run shredder from the bigquery-etl root.
script/shredder_delete
--billing-projects moz-fx-data-backfill-7
--source-project moz-fx-data-shared-prod
--target-project moz-fx-data-backfill-7
--start_date 2020-06-01
--only 'telemetry_stable.*'
--dry_runThis removes relevant rows from our final tables.
INFO:root:Scanned 515495784 bytes and deleted 1280 rows from moz-fx-data-backfill-7.telemetry_stable.crash_v4
INFO:root:Scanned 35301644397 bytes and deleted 45159 rows from moz-fx-data-backfill-7.telemetry_stable.event_v4
INFO:root:Scanned 1059770786 bytes and deleted 169 rows from moz-fx-data-backfill-7.telemetry_stable.first_shutdown_v4
INFO:root:Scanned 286322673 bytes and deleted 2 rows from moz-fx-data-backfill-7.telemetry_stable.heartbeat_v4
INFO:root:Scanned 134028021311 bytes and deleted 13872 rows from moz-fx-data-backfill-7.telemetry_stable.main_v4
INFO:root:Scanned 2795691020 bytes and deleted 1071 rows from moz-fx-data-backfill-7.telemetry_stable.modules_v4
INFO:root:Scanned 302643221 bytes and deleted 163 rows from moz-fx-data-backfill-7.telemetry_stable.new_profile_v4
INFO:root:Scanned 1245911143 bytes and deleted 6477 rows from moz-fx-data-backfill-7.telemetry_stable.update_v4
INFO:root:Scanned 286924248 bytes and deleted 10 rows from moz-fx-data-backfill-7.telemetry_stable.voice_v4
INFO:root:Scanned 175822424583 and deleted 68203 rows in totalAfter this is all done, we append each of these tables to the tables in the
production location. This requires super-user permissions, so this gets handed
off to another engineer to finalize the deed. Afterwards, we can delete the rows
in the error table corresponding to the backfilled pings from the backfill-7 project.
DELETE
FROM
`moz-fx-data-shared-prod.payload_bytes_error.telemetry`
WHERE
DATE(submission_timestamp) BETWEEN "2020-07-04"
AND "2020-08-20"
AND exception_class = 'org.everit.json.schema.ValidationException'
AND error_message LIKE '%GPUActive%'Finally, we update the production errors with new errors generated from the backfill process.
bq cp --append_table moz-fx-data-backfill-7:payload_bytes_error.telemetry moz-fx-data-shared-prod:payload_bytes_error.telemetryNow those rejected pings are available for analysis down the line. For the unadulterated backfill logs, see this PR to bigquery-backfill.
Conclusions
No system is perfect, but the processes that we have in place allows us understand the surface area of issues and to address failures in a systematic way. Our health check meeting improves our situational awareness of changes upstream in applications like Firefox, while our backfill logs in bigquery-backfill allows us to practice dealing with the complexities of recovering from partial outages. These underlying processes and systems are the same ones that faciliate the broader Glean ecosystem at Mozilla, and will continue to exist as long as the data flows.